There are several definitions of Big Data available but the specific definition is not available. Simply we can say Big Data is “the amount of data (structured and unstructured) just beyond technology's capability to store, manage, and processes efficiently." In other words, we can characterize the Big Data by four V's: Volume, Variety, Velocity, and Value.
Hadoop revolution started with two people, Mike Cafarella and Doug Cutting. Both were working on building a search engine system that can index 1 billion pages. They came across a paper which was published in 2003 that describes the architecture of Google's distributed file system (called GFS). After that google introduced MapReduce and published a research paper. These two paper led to the foundation of the framework called "Hadoop". In 2006, Yahoo created Hadoop based on GFS and MapReduce with Doug Cutting and team on a 1000 node cluster. Later in January 2008, Yahoo released Hadoop as an "Open-Source Project". Today, Hadoop's framework and ecosystem of technologies are managed by Apache Software Foundation.
Hadoop is an open source framework from Apache and is used to store and process the data. which is a very huge amount of data. Hadoop is written in JAVA that allows distributed processing of large datasets. Hadoop is developed for data processing applications which are executed in a distributed computing environment. It is being used by Facebook, Yahoo, Google, Twitter etc.
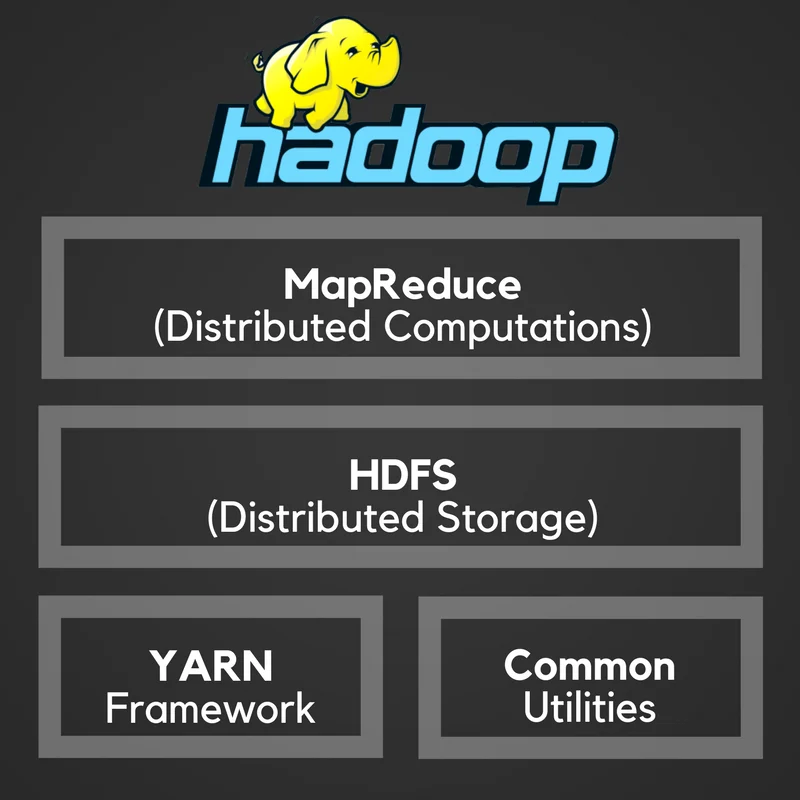
Hadoop Architecture:
MapReduce as the name implies it is a two-step process. There is a Mapper and Reducer programmers will write the mapper function which will go out and tell the cluster what data point we want to retrieve. The Reducer will then take all of the data and aggregate. All data in MapReduce flows in the form of key and value pairs, <key, value>.
Function | Input | Output |
Map | <Key1, Value1> | List(Key2, Value2) |
Reduce | <Key2, List(Value2)> | List(Key3, Value3) |
Hadoop Distributed File System (HDFS):
It is a storage component of Hadoop, which was designed and developed to handle large files efficiently. It is a distributed file system designed to work on a cluster and makes it easy to store large files by splitting files into blocks and multiple nodes. HDFS is written in Java and is a file system that runs within the user space.
Yet Another Resource Negotiator (YARN):
Yet Another Resource Negotiator (YARN) is used for job scheduling and manage the cluster. YARN is the foundation of the new generation of Hadoop (It means Hadoop 2.0), it helps organizations to use modern data architecture. Using Hadoop as the common standard for batch, interactive and real-time engines for YARN provide multiple access engines that can simultaneously access the same data set.
These are JAVA libraries and utilities which provides filesystem and OS level abstractions to start Hadoop.
Hadoop has two main component HDFS which stores the data while MapReduce processes the data and after integration gets the desired output.
Now understand how data stored in Hadoop:
Hadoop has HDFS and it used to store the data. For keep running of HDFS Hadoop has two daemons.
Namenode (Runs on the master node)
Datanode (Runs on the slaves)
Namenode daemons stored the metadata while Datanode daemons store the actual data. NameNode operates in a “loosely coupled” way with the data nodes. It means elements of the cluster can dynamically change node as par real-time server capacity which fits the system.
The data is broken into small chunks called as "blocks" and these blocks are stored distributedly on different nodes in the cluster. Blocks are divided as per the replication factor manner (By default replication factor is 3).
Now understand how data processed in Hadoop:
MapReduce is the processing layer of Hadoop, it has also two daemons:
Resource Manager that splits the job submitted by the client into small tasks.
Node ManagerNode Manager works data stored in Data Nodes which perform parallel distributed manner.
The client should submit the algorithm to the master node for data processing. Hadoop works on the principle of data locality ie. Instead of moving data to the algorithm, the algorithm is moved to Datanodes where data is stored.
Let's summarize how Hadoop works step by step:
Input data are broken into blocks of size 128 Mb and 64 Mb. then, blocks are moved to different nodes.
Once all the blocks of the data are stored on data-nodes, then start the further processing of data.
Resource Manager schedules the program on individual nodes.
Once all the nodes process the data, the output is written back to HDFS .
Hadoop is a scalable storage platform because it can store and distribute very large data sets across hundreds of inexpensive servers that operate simultaneously.
Hadoop doesn't depend on hardware which provides fault-tolerance and high availability (FTHA).
Hadoop has a unique storage system and its based on the distributed file system that’s why the resulting data storing and processing is very faster than other.
Large computing clusters are prone to failure of individual nodes in the cluster. Hadoop is fundamentally resilient – when a node fails processing is redirected to the remaining nodes in the cluster and data is automatically re-replicated in preparation for future node failures.
Apart from open source, Hadoop has another big advantage, which is Hadoop is compatible with all platform since it is JAVA based.




