As we all know, Replica is nothing but just a copy of something and the process to create a replica of something is called Replication. Now let’s define the term Database Replication.
Database Replication
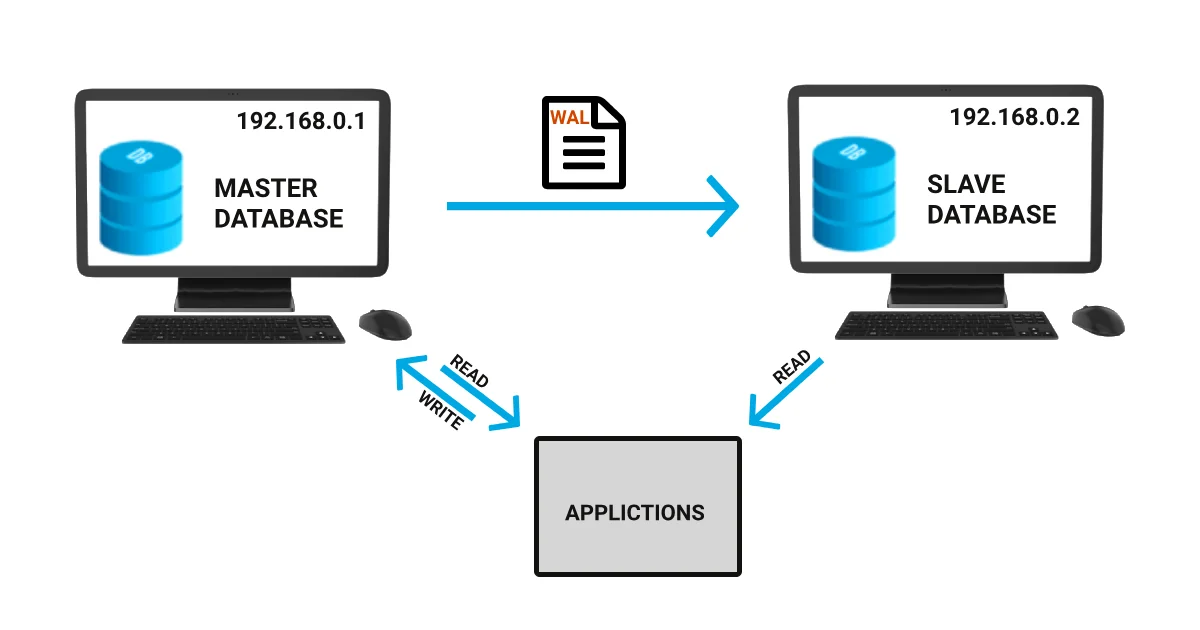
Database Replication is a technique to transfer the exact replica of each database instances from a database to other databases located in the same or different server to provide High availability of data and Load balancing on a server. We can refer the main database as Master Database and replicated database as Slave Database.
Benefits of Database Replication
- Improve Reliability: Data is available in more than one database server so if one server goes down because of some hardware/software issues, the data is still available on another replicated server and we can still serve our application from this database. So our application will not be crashed.
- Increased parallelism: The data will be served from more than one server So load will be divided and more requests can be processed at each instance of time.
Now, I am going to show how to configure database replication with PostgreSQL database server. Below are my system configuration details.
OS: ubuntu 14.04
PostgreSQL version: 9.3
There are many techniques available to configure replication in Postgres. Here we will cover Hot standby technique of PostgreSQL to replicate the database.
Hot Standby Technique
Any updates will be made in the master server will be propagated to slave server as a form of WAL (Write Ahead Logging) files. On the master server, we can perform read/write both operations on a database. Slave database is used for read-only queries. When the master is crashed then we can configure our slave server as a master server.
High-level Steps:
- Install Postgres in both servers and configure postgres user
- Configure Master Server
- Configure Slave Server
- Replicating the initial Database
- Recovery Configuration
Step 1: Install Postgresql in both master and slave server and configure postgres user
sudo apt-get update
sudo apt-get install postgresql
Set password of postgres user
Switch to postgres user
NOTE: Please follow all steps shown below with postgres user
Step 2: Configure Master Server
Create a replication user which have replication privileges. We will use this user for the replication authentication afterward.
psql -c "CREATE USER replication_user REPLICATION LOGIN ENCRYPTED PASSWORD ' replication_user_password';"
Now, Authenticate the slave server to access master server. In PostgreSQL, Authentication is handled by pg_hba.conf file. Let's open the pg_hba.conf file.
nano /etc/postgresql/9.3/main/pg_hba.conf
We need to add below entry for the slave server shown as below: (In our example, IP_address_of_slave is replaced by 192.168.0.2)
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_address_of_slave/32 md5
Add hot_standby replication configuration in postgresql.conf file.
nano /etc/postgresql/9.3/main/postgresql.conf
Uncomment below line and do the changes like below:
listen_addresses = 'localhost, IP_address_of_current_host'
wal_level = hot_standby
max_wal_senders = 3
wal_keep_segments = 32
- listen_addresses: we will add Current (Master) server’s IP address (As per example image, IP_address_of_master is replaced by 192.168.0.1)
- wal_level: it is used to specify the replication method of postgres. Here, We have used hot_standby. It will enable read-only queries on standby(slave) server.
- max_wal_senders: To specify the maximum number of simultaneously running WAL sender processes from master to slave server.
- wal_keep_segments: Specifies the minimum number of past log file segments kept in the pg_xlog directory. If any wal file transmission fails then we can recover from these past logs.
Restart the master server to implement your changes
service postgresql restart
Step: 3 Configure Slave Server
Begin on the slave server by shutting down the Postgres database software:
Now, Authenticate the master server to access slave server. Let's open the pg_hba.conf file.
nano /etc/postgresql/9.3/main/pg_hba.conf
We need to add an entry for the slave server as per below: (In our example, IP_address_of_master is replaced by 192.168.0.1)
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_address_of_master/32 md5
Add hot_standby replication configuration in postgresql.conf file.
nano /etc/postgresql/9.3/main/postgresql.conf
Uncomment below line and do the changes like below:
listen_addresses = 'localhost, IP_address_of_current_host'
wal_level = hot_standby
max_wal_senders = 3
wal_keep_segments = 32
hot_standby = on
- listen_addresses: We will add Current (slave) server’s IP address (As per example image, we can put 192.168.0.2 in place of IP_address_of_current_host)
- hot_standby: To configure it as standby(slave) server
Restart the slave server to implement your changes
service postgresql restart
Step 4: Replicating the Initial database from Master to Slave server:
Please make sure, PostgreSQL service is in running state in the master server
First, we need to empty the data dir of the slave server and then we will replicate an initial database from master to slave server.
Perform below command in the slave server
rm -rf /var/lib/postgresql/9.3/main/*
Now the slave is ready to restore an initial master database. Please execute below command in slave server.
pg_basebackup -h IP_address_of_master -D /var/lib/postgresql/9.3/main -P -U replication_user --xlog-method=stream
It will ask you to enter a password. Please enter the password of replication_user.
Step 5: Recovery Configuration
Now we will configure recovery file in the slave server
nano /var/lib/postgresql/9.3/main/recovery.conf
Insert below code in opened file:
standby_mode = 'on'
primary_conninfo = 'host=IP_address_of_master port=5432 user=replication_user password=replication_user_password'
trigger_file = '/tmp/postgresql.trigger.5432'
- standby_mode: If this param is set to on then slave server will keep trying to continue recovery by fetching new WAL segments from Master server.
- primary_conninfo: Specifies a connection string to be used for the standby server to connect with the master server. (As per example, IP_address_of_master is replaced by 192.168.0.1)
- trigger_file: Whenever the master server goes down, you can reconfigure the slave server as a master by this command. For this, you need to create a file at the location specified in this param. And by this, your slave will reconfigure itself as master.
Start the slave server
That’s it. You can test your master-slave replication by executing any DDL/DML statements in master server. And you can see the same data is also available in slave server.
Conclusion
Data is always available for our application. If the master server is down due to some hardware/software fault, then we can reconfigure one of the slave servers as a master server. We can balance a load on our server by splitting reads between master and slave servers. This is how it’s used to improve the performance and it’s highly reliable.




